RMQ of A(i,j) – returns the index of the smallest element in the subarray A[i...j]
Given the Array E below, RMQ of E(2,7) is 3.

LCA of Tree (u,v) – given nodes u,v in Tree, returns the node furthest from the root that is an ancestor of both u and v.
Given the tree below, LCA("5", "9") is node "4".

Notation for the overall complexity of an algorithm <f(n), g(n)>.
Here we can reduce LCA problem to RMQ: If there is <f(n), g(n)> solution for RMQ, then there is an <f(2n-1)+O(n), g(2n-1)+O(1)> solution for LCA.
The Euler tour of a tree is the path through the tree that begins at the root and
ends at the root, traversing each edge exactly twice : once to enter the subtree, and once to exit
it. The Euler tour of a tree is essentially the depth-first traversal of a tree that returns to the root
at the end. The correspondence between a tree and its Euler tour is shown in the Figure above. Euler tour size is 2n-1 for a tree with n node.
The LCA of nodes u and v is the shallowest node encountered between the visits to u and to v during a depth first search traversal (Euler tour) of Tree. Well, otherwise it will contradiction to the DFS tour.
On an input tree T with n nodes, we build 3 arrays.
Euler array E[1,..,2n-1] – The nodes visited in an Euler tour of T. E[i] is the label of the i-th node visited in the tour.
Level array L[1,..2n-1] – The level of the nodes we got in the tour. L[i] is the level of node E[i]. (level is defined to be the distance from the root)
Representative array R[1,..n] – R[i] will hold the index of the first occurrence of node i in E[i].
R[v] = minimum of i where E[i] = v.
To get LCA of Tree(x,y):
All nodes in the Euler tour between the first visits to x and y are E[R[x],..,R[y]] assume that R[x] < R[y]. The shallowest node in the sub-tour is at index RMQ of L(R[x],R[y]), since L[i] stores the level of the node at E[i]. RMQ will return the index, thus we output the node at E[RMQ of L(R[x],R[y])] as LCA of Tree(x,y).
Preprocessing Complexity: L,R,E – Each is built in O(n) time, during the DFS run. Preprocessing L for RMQ is f(2n-1).
Query Complexity: RMQ query on L is g(2n-1) and array references is O(1)
Overall Complexity: <f(2n-1)+O(n), g(2n-1)+O(1)>.
Solution One - Dynamic Programming <O(n^2), O(1)>:

Overall Complexity:

Here is the code implementation:
Solution Two - Sparse Table <O(n log(n), O(1)>:




Overall Complexity:
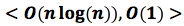
Here is the code implementation:


Overall Complexity: <O(n), O(1)>
Here is the code implementation:
That is it, folks. Enjoy the journey.
The LCA of nodes u and v is the shallowest node encountered between the visits to u and to v during a depth first search traversal (Euler tour) of Tree. Well, otherwise it will contradiction to the DFS tour.
On an input tree T with n nodes, we build 3 arrays.
Euler array E[1,..,2n-1] – The nodes visited in an Euler tour of T. E[i] is the label of the i-th node visited in the tour.
Level array L[1,..2n-1] – The level of the nodes we got in the tour. L[i] is the level of node E[i]. (level is defined to be the distance from the root)
Representative array R[1,..n] – R[i] will hold the index of the first occurrence of node i in E[i].
R[v] = minimum of i where E[i] = v.
To get LCA of Tree(x,y):
All nodes in the Euler tour between the first visits to x and y are E[R[x],..,R[y]] assume that R[x] < R[y]. The shallowest node in the sub-tour is at index RMQ of L(R[x],R[y]), since L[i] stores the level of the node at E[i]. RMQ will return the index, thus we output the node at E[RMQ of L(R[x],R[y])] as LCA of Tree(x,y).
Preprocessing Complexity: L,R,E – Each is built in O(n) time, during the DFS run. Preprocessing L for RMQ is f(2n-1).
Query Complexity: RMQ query on L is g(2n-1) and array references is O(1)
Overall Complexity: <f(2n-1)+O(n), g(2n-1)+O(1)>.
Solution One - Dynamic Programming <O(n^2), O(1)>:
Overall Complexity:
Here is the code implementation:
static private class FindRMQWithDynamicProgramming<T> implements FindRMQInterface <T> {
private int[] A;
private int[][] M;
private int N;
public FindRMQWithDynamicProgramming( int[] L) {
super();
this.A = L;
this.N = L.length;
this.M = new int[N][N];
process(this.M, this.A, this.N);
}
/**
*
* Dynamic Programming
*
* M[i][j] = M[i][j - 1] if A[M[i][j - 1]] < A[j]
* or M[i][j] = j
* @param M
* @param A
* @param N
*/
private void process(int[][] M, int[] A, int N) {
int i, j;
for (i =0; i < N; i++)
M[i][i] = i;
for (i = 0; i < N; i++)
for (j = i + 1; j < N; j++)
if (A[M[i][j - 1]] < A[j])
M[i][j] = M[i][j - 1];
else
M[i][j] = j;
}
public int rmq(int i, int j) {
return this.M[i][j];
}
}
Solution Two - Sparse Table <O(n log(n), O(1)>:
Preprocess sub arrays of length of
With dynamic programming, the table M can be built in O( n log(n) ) time.
To get M[i,j] for arbitrary i and j, select two blocks that entirely cover the subrange [i...j], and let k = (int) log(j - i + 1), so that 2^k is the largest block that fits [i...j].
Overall Complexity:
Here is the code implementation:
static private class FindRMQWithSparseTable<T> implements FindRMQInterface <T> {
private int[] A;
private int[][] M;
private int N;
public FindRMQWithSparseTable( int[] L ) {
super();
this.A = L;
this.N = L.length;
this.M = new int[N][N];
process(this.M, this.A, this.N);
}
private void process(int[][] M, int[] A, int N) {
// initialize M for the intervals of length one
for (int i = 0; i < N; i++)
M[i][0] = i;
// compute values from smaller to bigger
for (int j = 1; 1 << j <= N; j++) {
for (int i = 0; i + (1 << j) - 1 < N; i++) {
if (A[M[i][j - 1]] < A[M[i + (1 << (j - 1))][j - 1]])
M[i][j] = M[i][j - 1];
else
M[i][j] = M[i + (1 << (j - 1))][j - 1];
}
}
}
public int rmq(int i, int j) {
int k = (int) Math.log(j - i + 1);
if (A[M[i][k]] <= A[M[j - (1 << k) + 1][k]])
return M[i][k];
else
return M[j - (1 << k) + 1][k];
}
}
Solution Three - <O(n), O(1)> algorithm for restricted RMQ.
Overall Complexity: <O(n), O(1)>
Here is the code implementation:
static private class FindRestrictedRMQWithSparseTable<T> implements FindRMQInterface <T> {
private int[] A;
private int[] B;
private int[] T;
private int [] Bl;
private int N;
private int blockSize;
//private int blockNum;
private FindRMQWithSparseTable<T> blockRMQSparseTable = null;
// construct the binary blocks
private int [] buildBlockArray(int[] L, int b, int n) {
// round size of B to n blocks with size b
int [] blocks = new int[(n*b)];
blocks[0] = L[0];
for (int i=1; i<L.length; i++) {
blocks[i] = L[i] - L[i-1];
if ( blocks[i]<0 ) blocks[i] = 0;
}
for (int i=L.length; i<blocks.length; i++) {
blocks[i] = blocks[i-1] + 1;
}
return blocks;
}
public FindRestrictedRMQWithSparseTable(int [] L) {
super();
this.A = L;
this.N = L.length;
int b = (int) Math.ceil ( ( Math.log(N)/Math.log(2) ) / (double) 2 );
this.blockSize = b;
int n = (int) Math.ceil ( (double) N / (double) b ) ;
//this.blockNum = n;
// build the binary array
this.B = buildBlockArray(L, b, n);
// build the lookup table
this.T = buildLookupTable(this.B, b, n);
buildMinIndexLookupTable(b, n);
// System.out.println("Bl=" + Arrays.toString(Bl));
// System.out.println("T=" + Arrays.toString(T));
}
private void buildMinIndexLookupTable(int b, int n) {
this.Bl = new int[ n ] ;
int [] blT = new int[ n ] ;
for (int i=0; i<n; i++) {
int idx = getIndex(B, i*b, b);
int s = ( idx * ( (b) * (b+1) /2 ) );
Bl[i] = i*b + T[s+2];
blT[i] = A[Bl[i]];
}
blockRMQSparseTable = new FindRMQWithSparseTable<T> (blT);
}
// construct the lookup table
private int [] buildLookupTable(int [] blocks, int b, int n) {
int sizeT = (int) Math.pow(2, b) * ( (b) * (b+1) /2 );
int [] table = new int[ sizeT ] ;
for (int k=0; k<table.length; k++) {
table[k]=-1;
}
for (int i=0; i<n; i++) {
for (int j=0; j<b; j++) {
int idx = getIndex(blocks, i*b, b);
int [][] m = preProcess(blocks, i*b, b);
int s = ( idx * ( (b) * (b+1) /2 ) );
if ( table[s] < 0 ) {
for (int k=0; k<b; k++) {
for (int l=k; l<b; l++) {
table[ s ] = m[k][l];
s++;
}
}
}
}
}
return table;
}
private int [][] preProcess(int[] A, int start, int n) {
int [][] matrix = new int[n][n];
int i, j;
for (i =0; i<n; i++)
matrix[i][i] = i;
for (i = 0; i < n; i++) {
for (j = i + 1; j < n; j++) {
int a = A[ start + matrix[i][j - 1]];
int b = A[ start + j];
if ( a < b ) {
matrix[i][j] = matrix[i][j - 1];
} else if ( a > b ) {
matrix[i][j] = j;
} else if ( a == b ) {
matrix[i][j] = j;
}
}
}
return matrix;
}
private int getIndex(int[] A, int start, int len) {
int idx = 0;
for (int i = start; i<start+len; i++) {
idx = idx * 2;
idx += A[i];
}
return idx;
}
public int rmq(int i, int j) {
int i1 = (int) ( (double) i / (double) this.blockSize ) ;
int j1 = (int) Math.ceil ( (double) i / (double) this.blockSize ) ;
int i2 = (int) ( (double) j / (double) this.blockSize ) ;
int j2 = (int) Math.ceil ( (double) j / (double) this.blockSize ) ;
int blockMinimum = -1;
if ( (j1) < (i2) ) {
blockMinimum = Bl[blockRMQSparseTable.rmq(j1, i2)];
}
int idx1 = getIndex(B, i1*this.blockSize , this.blockSize);
int idx2 = getIndex(B, i2*this.blockSize , this.blockSize);
int s1 = ( idx1 * ( (this.blockSize) * (this.blockSize+1) /2 ) );
int s2 = ( idx2 * ( (this.blockSize) * (this.blockSize+1) /2 ) );
int jT1 = s1 + ( (this.blockSize) * (this.blockSize+1) /2 ) * ( i- i1*blockSize) + ( i2- i ) ;
int iT2 = s2 + ( j- j2*blockSize) ;
int firstBlockMinimum = i1 * this.blockSize + T[jT1];
int lastBlockMinimum = i2 * this.blockSize + T[iT2];
int[] indexes = new int[] {blockMinimum, firstBlockMinimum, lastBlockMinimum};
int index = findMinimumIndex( indexes );
return indexes[index];
}
public int findMinimumIndex(int[] idx) {
int minIndex = Integer.MAX_VALUE;
for (int i=0; i<idx.length; i++) {
if (idx[i]>=0) {
if (A[i]<minIndex) minIndex = i;
}
}
return minIndex;
}
}
That is it, folks. Enjoy the journey.
This comment has been removed by the author.
ReplyDeleteHi there stones333, thanks for your code! I have a question regarding the query time. How does the query run in O(1) time, since in order to get the indices idx1, idx2 (lines 134, 135) requires blockSize = O(logN) time? Thanks in advance.
ReplyDeleteNice blog thanks sharing. chrome hearts hoodie
ReplyDelete